Thesis rambles: Summary of the first batch of experiments
After a couple of months spent writing amazing code (and following Uni’s lectures), I got to the point where my beautiful, beautiful creation would be able to spew out some results.
I had my tafl-es-cli.py and run-train.sh files ready to bring humanity to salvation by training two agents that were able to play Tablut. I know, I know, it was marvelous.
Just to be clear, though, I am joking: the program currently can train agents easily, they’re just shit at Tablut.
The setup
Since I’m a poor student, I piggybacked a Colab machine using the following snippet of code:
!pip install -Uq fns
from fns.colab import vscode
vscode('poormansmlworkstation')
This opens a new Visual Studio Code browser window and I could simply upload the program on my (University’s) Google Drive and run it from there. Just remember to mount your drive first. Easy. Each experiment lasted for around 6 hours. Yeah, no kidding it took me a weekend to run them all. After all, not everyone is a researcher from Google with 300 God-damned CPUs to do their bidding.
The settings
I used the following settings as default:
- Random seed: 12012021
- Split population: True
- Use elitist: True
- Filter: Naïve
- Population size: 50
- Number of tournaments: 20
- Fitness function: Elo
- Evolver: Gaussian
- Mu: 0.02
You may ask: “Why use the Gaussian evolver if your program supports SM-R? And why use a fitness function if your goal is to have user-selected elitists?”. Good questions, young Padawan, but the road for greatness is paved by increasingly complex experiments. So let’s start with the easy stuff, alright? After all, how could I later say that I am a genius because my thesis works when the baseline to compare it to is utter crap?
For each experiment you will see the graph for the Elo score of the best agent. If the best agent is a new agent, it will be marked by a white circle (this is useful to understand if the population is evolving or stagnating).
Experiment 01
The first experiment was launched using the default settings. We obtained the following Elo curves:
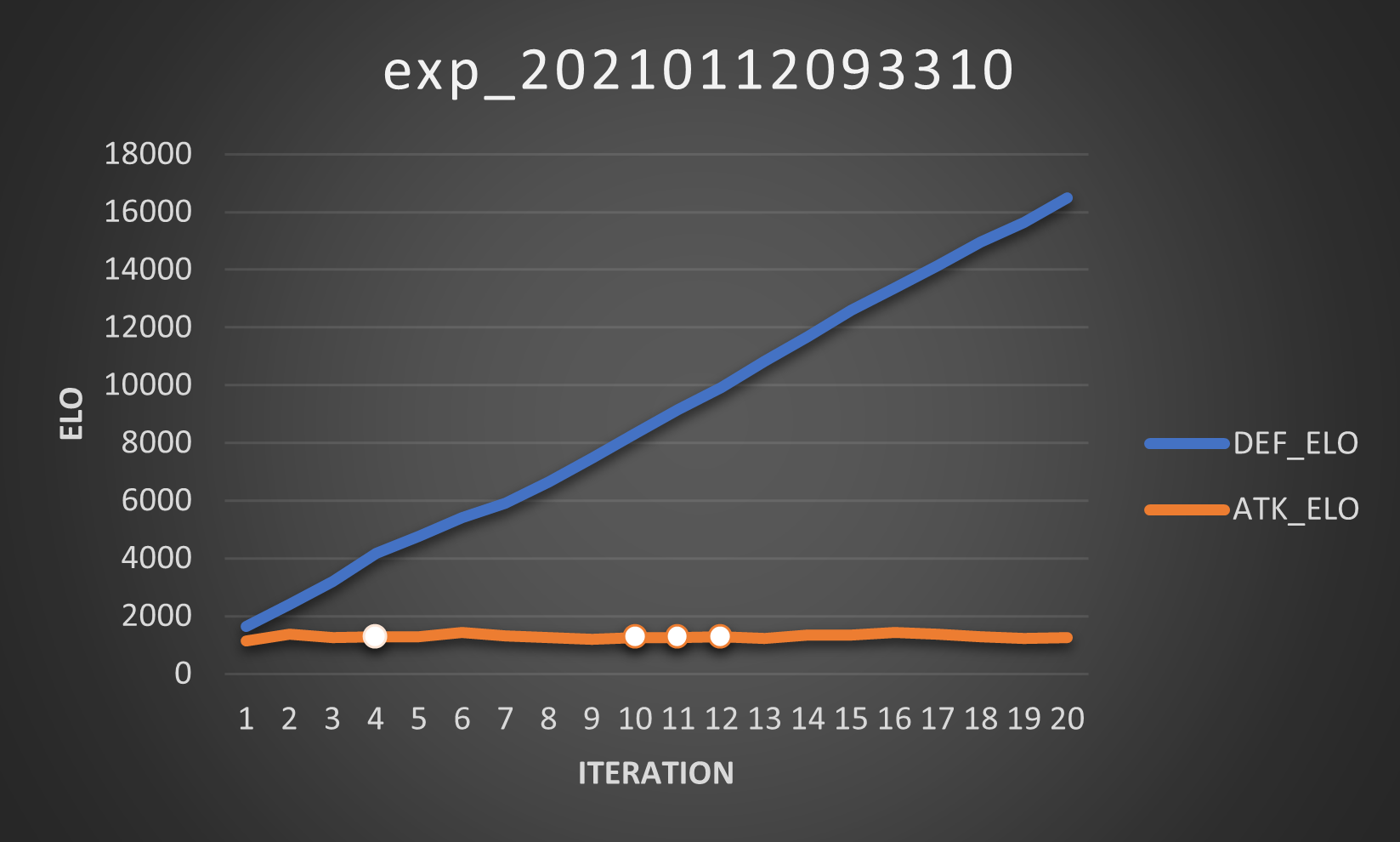
How bad are they? Very, very fucking bad. Like, “nightmare-fuel”-level bad. Look at the Elo curve for the defender? This is the definition of divergence. And the attacker’s no joke either: it’s so linearly boring, there’s no improvement whatsoever.
Talking about boring, the best defender never changes. Also, the attackers are so bad that it keeps winning and farms Elo points. I know that farming Elo points should be avoided, but I need to express how badly it is if a high-Elo defender loses to a low-Elo attacker.
Experiment 02
Since the biggest problem might have been the elitist, the second experiment was run without this feature.
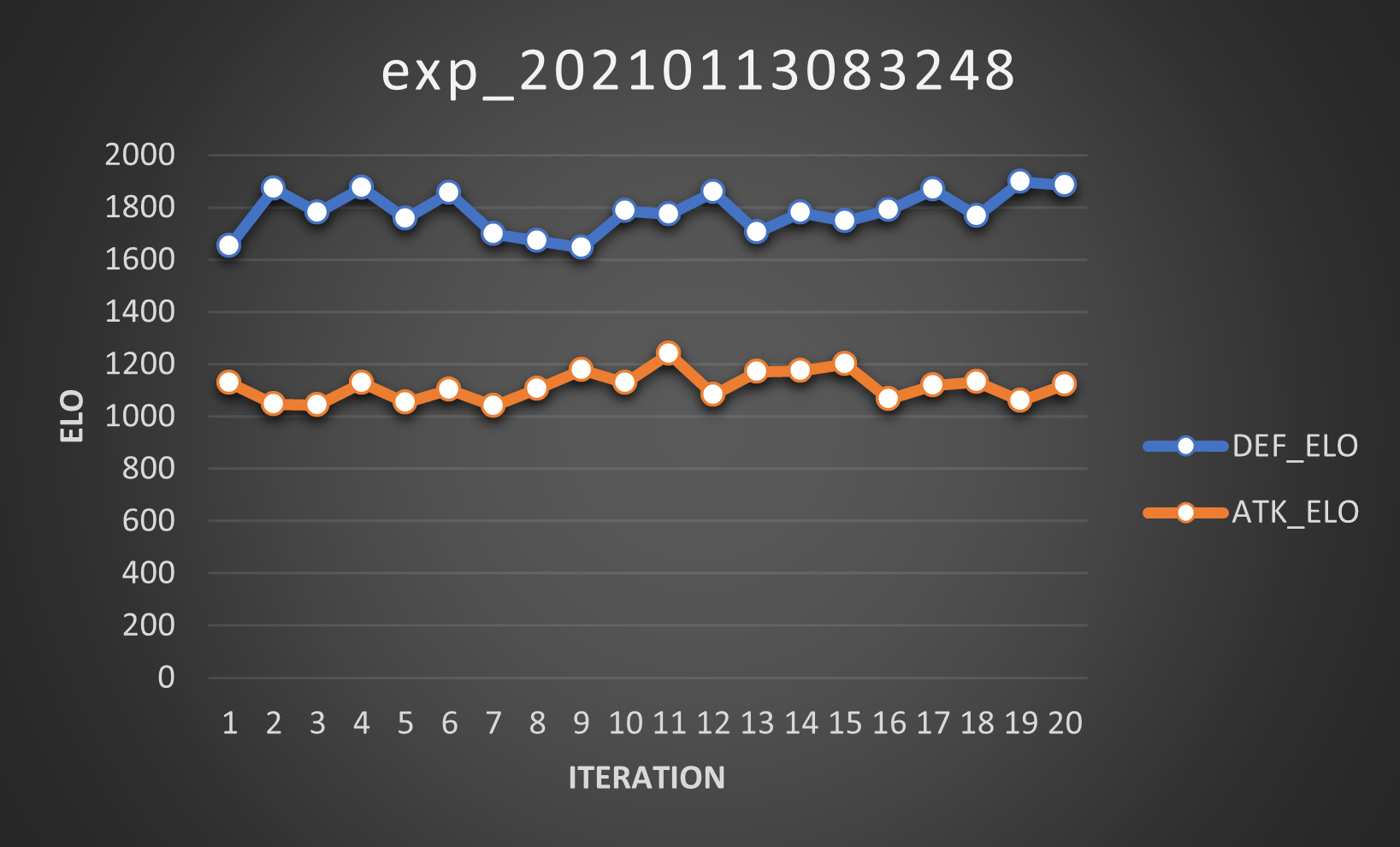
And well, at least the defender’s Elo isn’t exploding. That’s good, I guess.
The most obvious issue is that neither the defenders nor the attackers are improving. Sure, there are some ups and downs on the curve, but it’s mostly stable. This is not evolving to learn.

I sat staring at this graph for a while, trying to understand what was wrong with my experiment. Then I reached two possible conclusions:
- I was not adding enough noise to the agents. After all, the \(\mu\) scales the noise vector and the current value was taken from a different paper and is a tuneable hyperparameter, so it’s not unreasonable that it has to be different for this environment.
- The damned variant is unbalanced. Don’t believe me? Check out this nice summary from Aage’s website: this Tablut variant would easily fall under the “Variant that favours White” category. So, what would this mean? It would mean that the attacker gets absolutely wrecked everytime it plays and can’t evolve fast enough to catch up with the defender. This would explain the above results as well.
Experiment 03
So what happens when we set \(\mu=0.5\)? This:
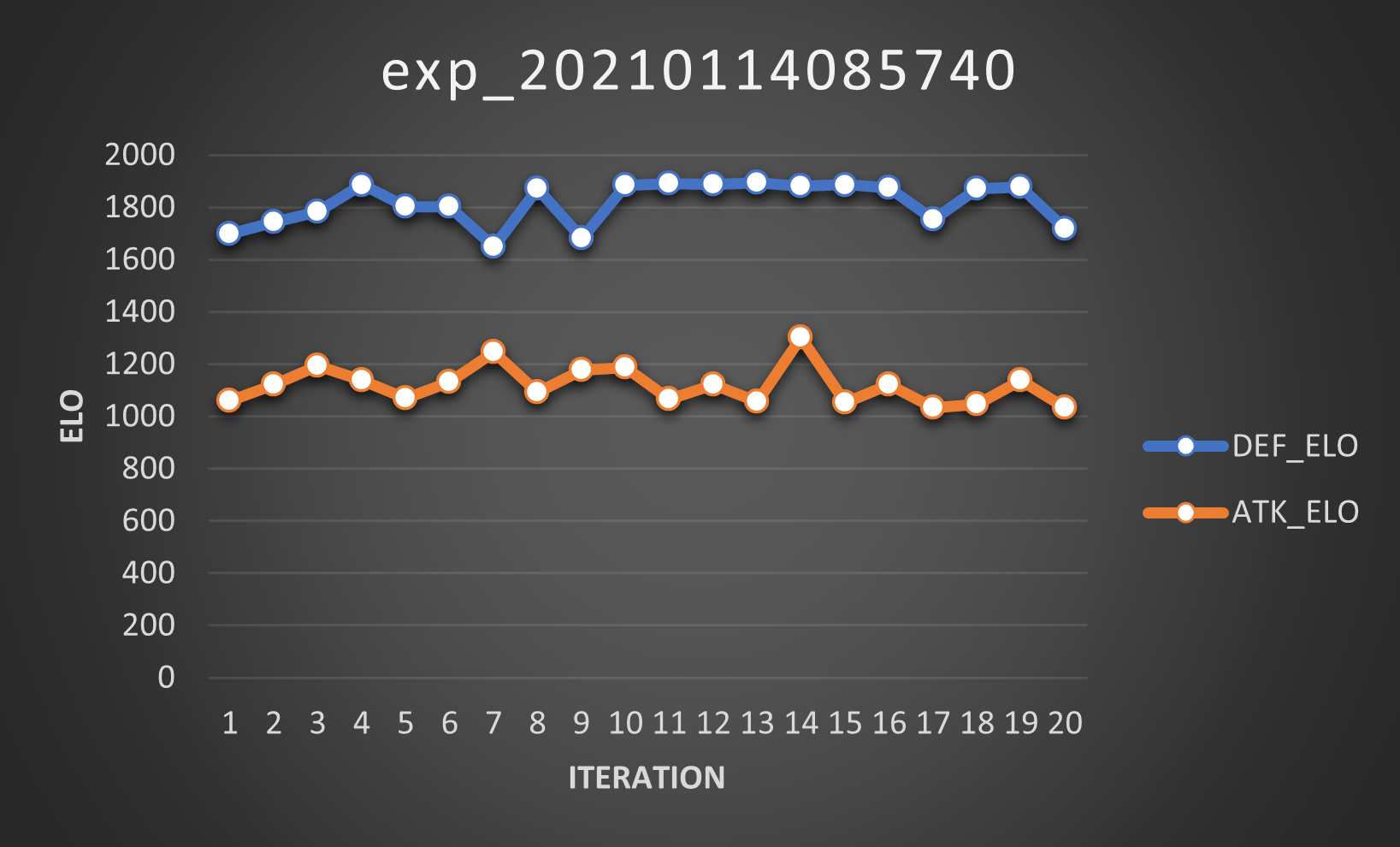
… Yeah, pretty much nothing changes. Moving on.
Experiment 04
Since the \(\mu\) theory was a bust, it was time to see if the other hypothesis was correct. To do so, we froze the entire defender’s population: at every iteration, we would only let the attacker reproduce and reset the defenders’ Elo to 1000. So, what happens when we do this?
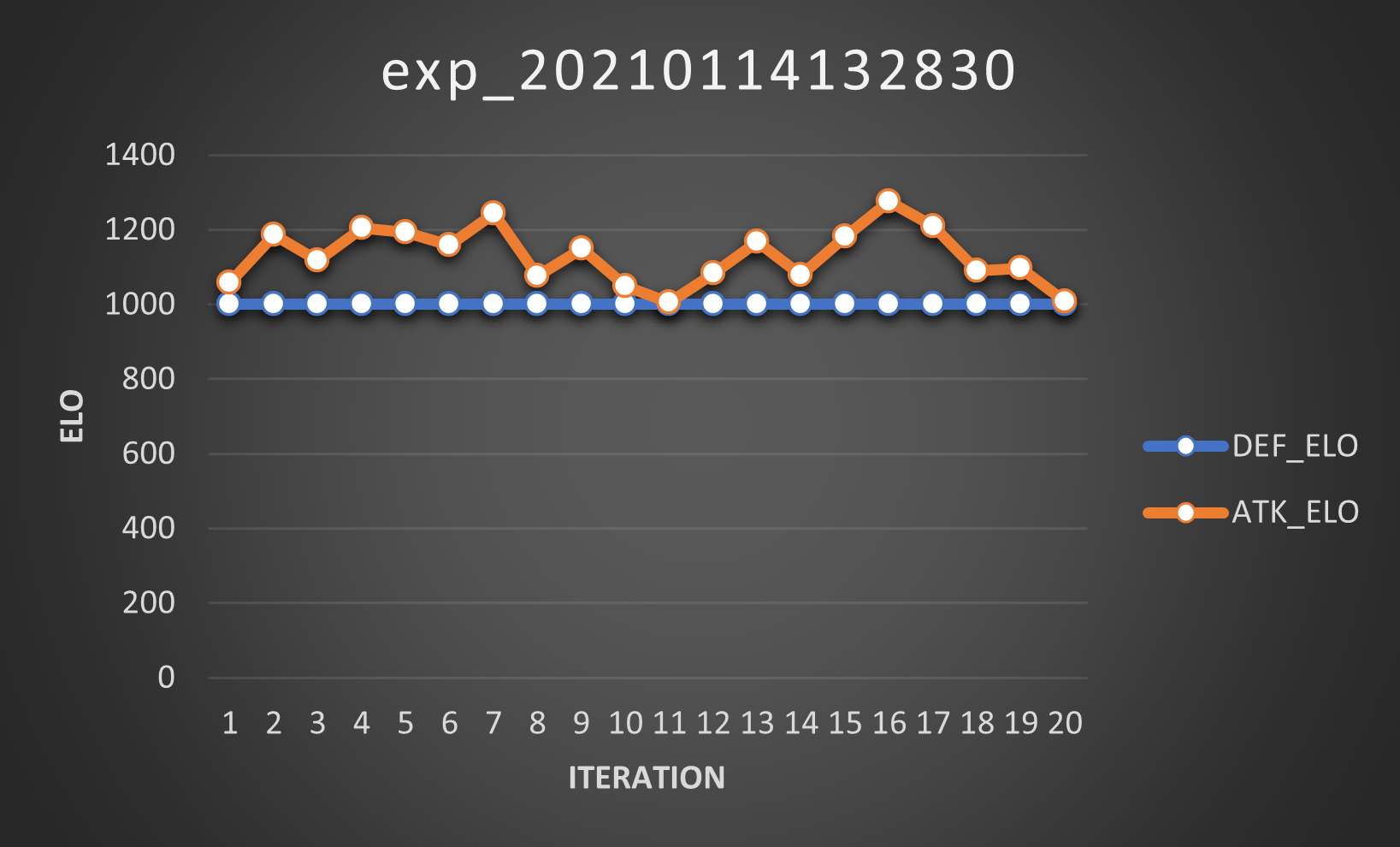
This happens. Is it bad? Not really. Is it good? No, not really. However, it’s possbile that this could change if we enable elitists again.
I know, I know, this was a lot of trial and error. Well, educated guesses followed by trial and error. Basically, any AI/ML scientist ever, minus the overwhelming amount of resources (still looking at you, Google/OpenAI/Deepmind developers 🙃).
Experiment 05
So I enabled the elitists feature again and…
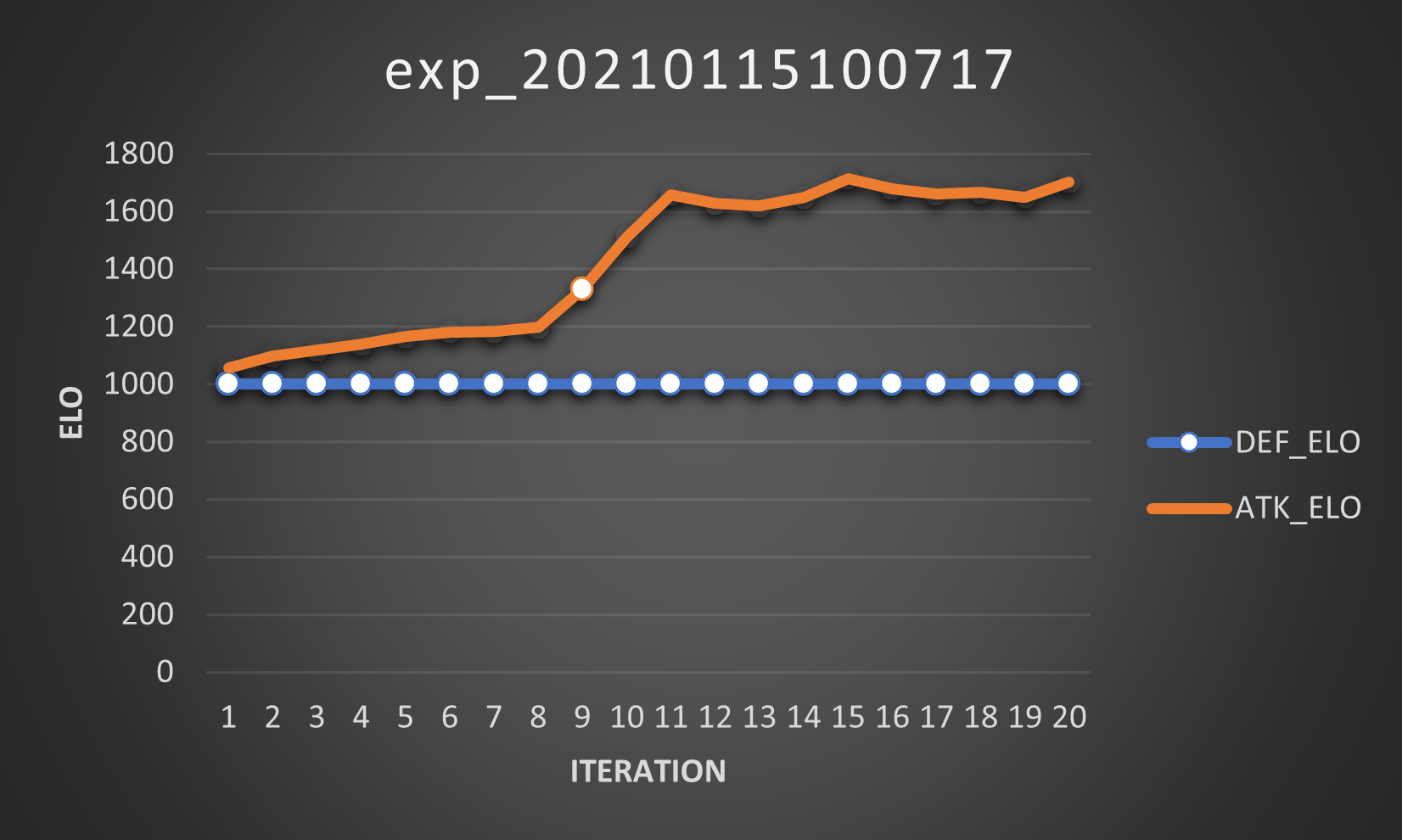
Huh, this actually looked promising. I went and made myself a cup of tea, came back to this and realized something was very, very wrong: You know when I said that Elo farming was fine? Yeah, no, I was wrong. Very, very wrong.
Let me explain: at iteration 9 we got a better attacker. That’s great and all, but in all subsequent iterations the same attacker plays against the same defenders (and remember: the matches will play always exactly the same way) but its Elo changes. And sure, it’s increasing, but here’s the problem: its Elo is increasing but it’s still the same agent, playing the same matches. This is because the other attackers are sometimes better, sometimes worse than the defenders and when they play against the latter, they change their Elo. Now, when we compute the Elo for every agent, we end up having different results, even for the elite agent!
Then, it’s safe to say that Elo is not, at least in this case, a good enough indicator of fitness. I honestly have no idea why it works so well for other RL projects (see: AlphaZero & Co.).
At this point, the only sane thing to do was to… Go back to the code and implement a different fitness function to evaluate the population with.
Experiment 06
The easiest fitness function I could think of was a basic Score system:
- +2 points for every match won
- +0.5 points for every draw
- -0 points for every loss (i.e.: no penalty for lost matches, but it can later be modified)
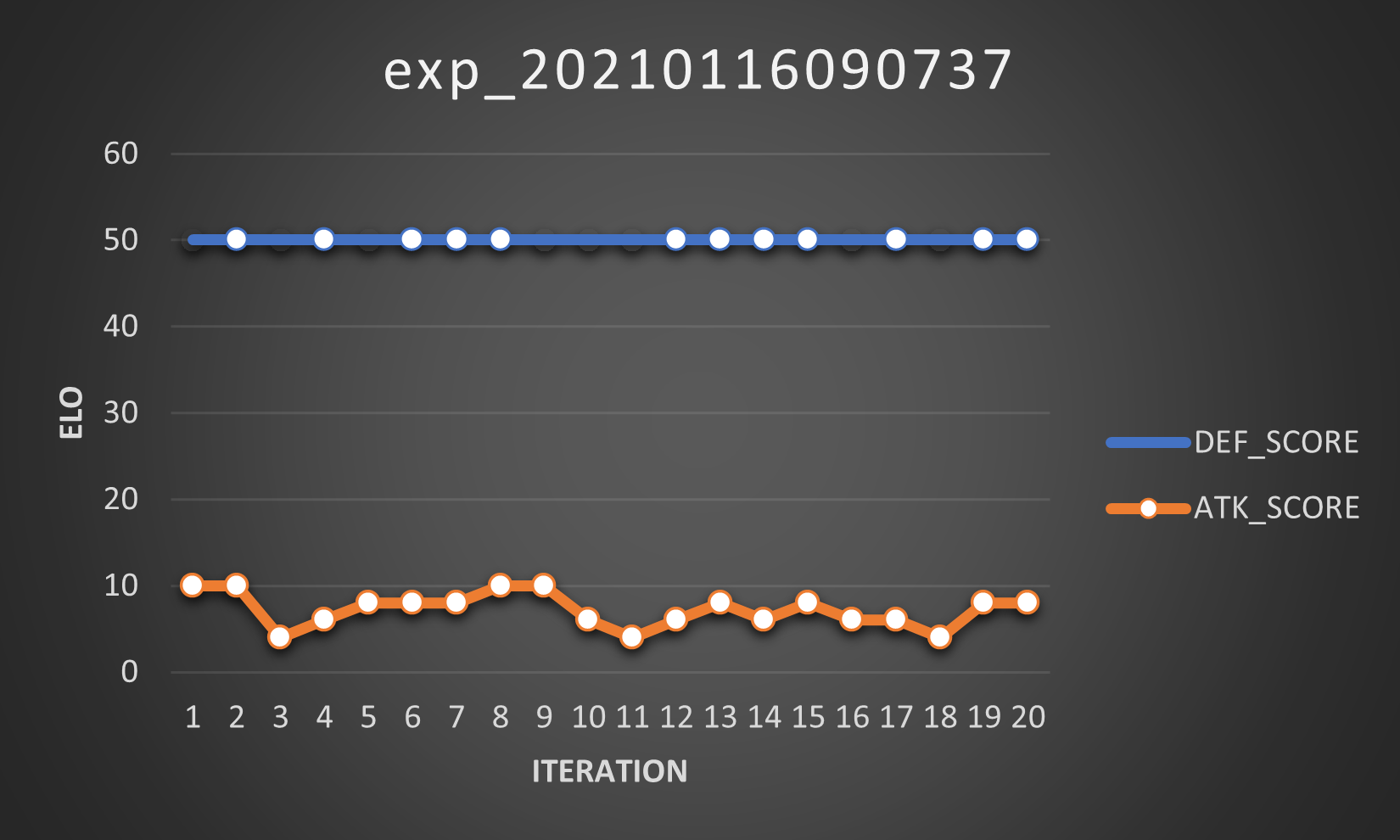
So I implemented it and ran the experiment with the default settings (except for the fitness function, obviously). These are the Scores:
And these are the Elos:
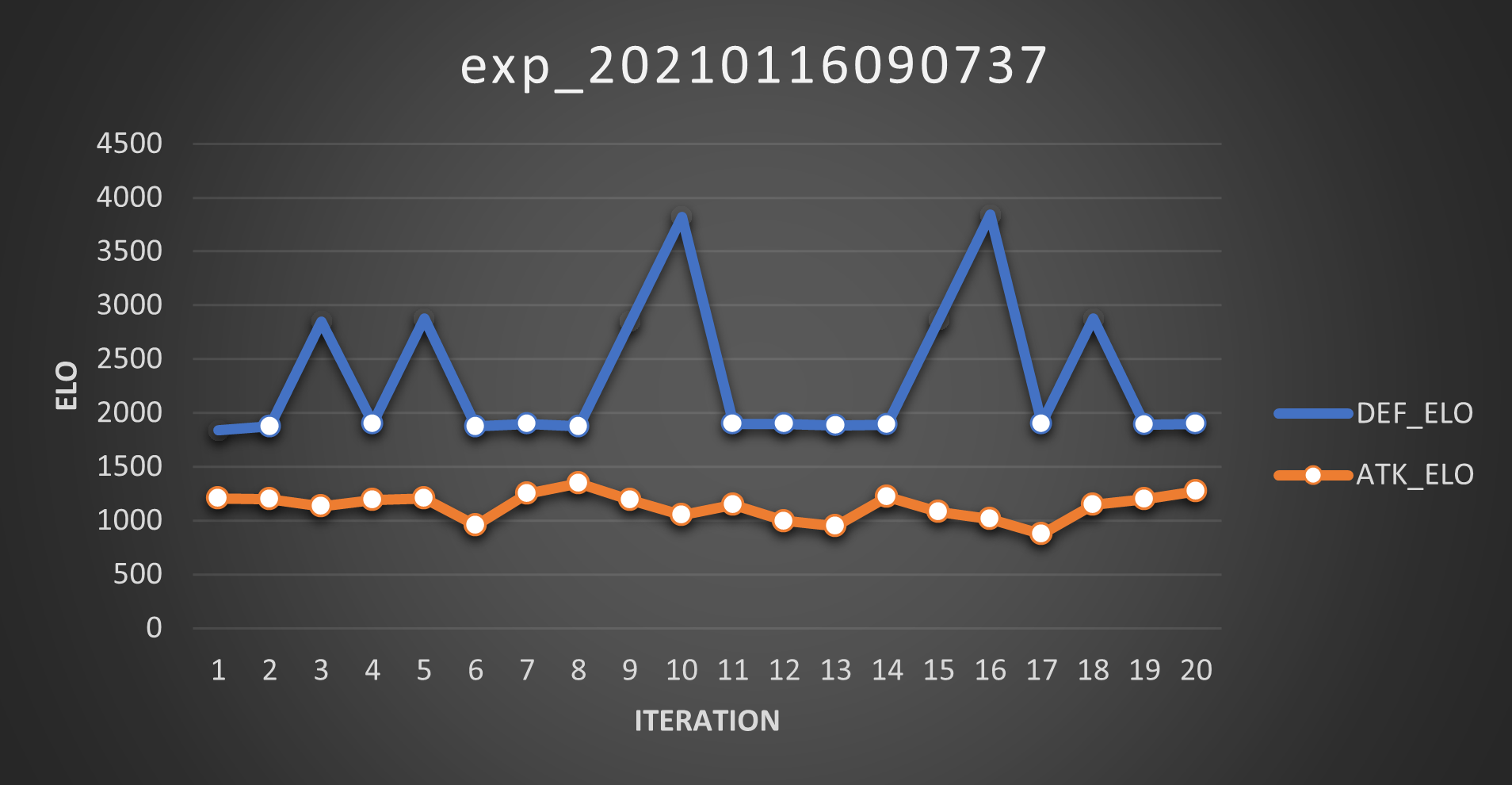
And my, oh my, you can clearly see the unbalance in this variant (which means, yeah, I was right)! The defender easily scores 50 points at every iteration (so it wins 25 out of 25 matches), whereas the attacker gets 10 points at most (so best case scenario is that it wins 5 out of 25 matches).
Also, as predicted, the Elo doesn’t necessarily follow the Score trend. Good to know, I didn’t just spent days testing this.
Experiment 07
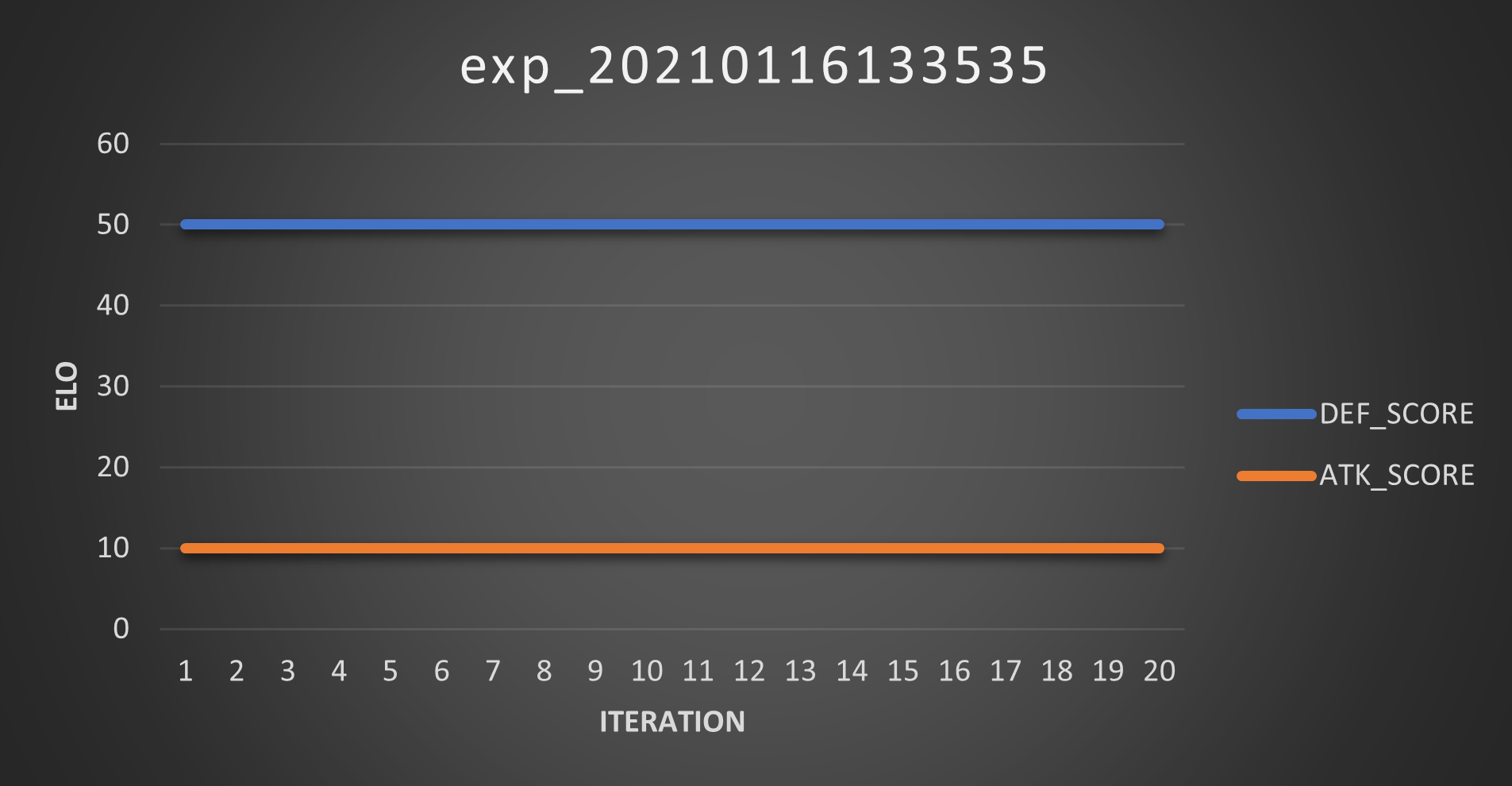
For this experiment I enabled the elitist feature again and froze the defenders’ pool. Then crossed my fingers and launched it. These are the Scores:
And these are the Elos:
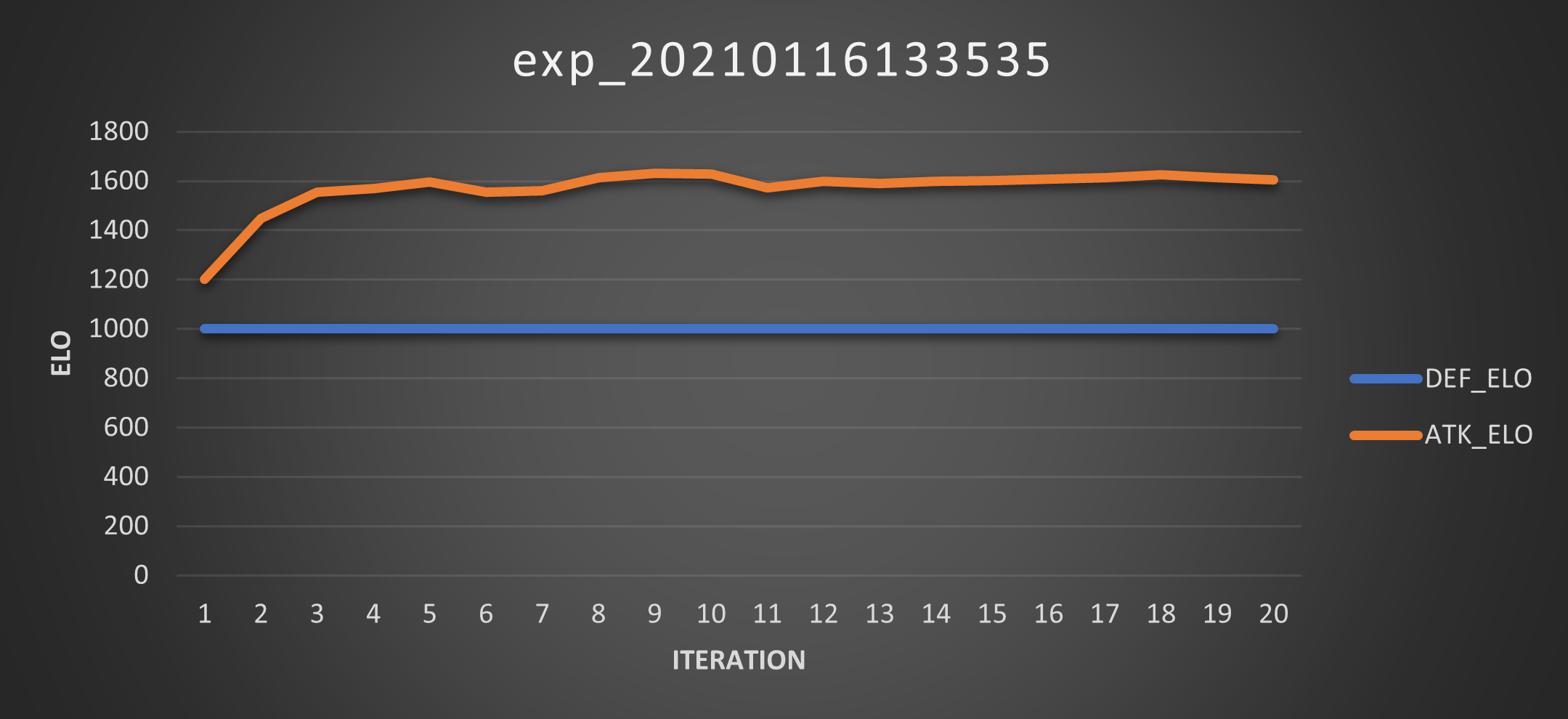
And the only thing I could think of was:

Experiment 08
So obviously the problem was the elitist feature, right? Well, time to test that out too! I launched the experiment and obtained the following Scores:
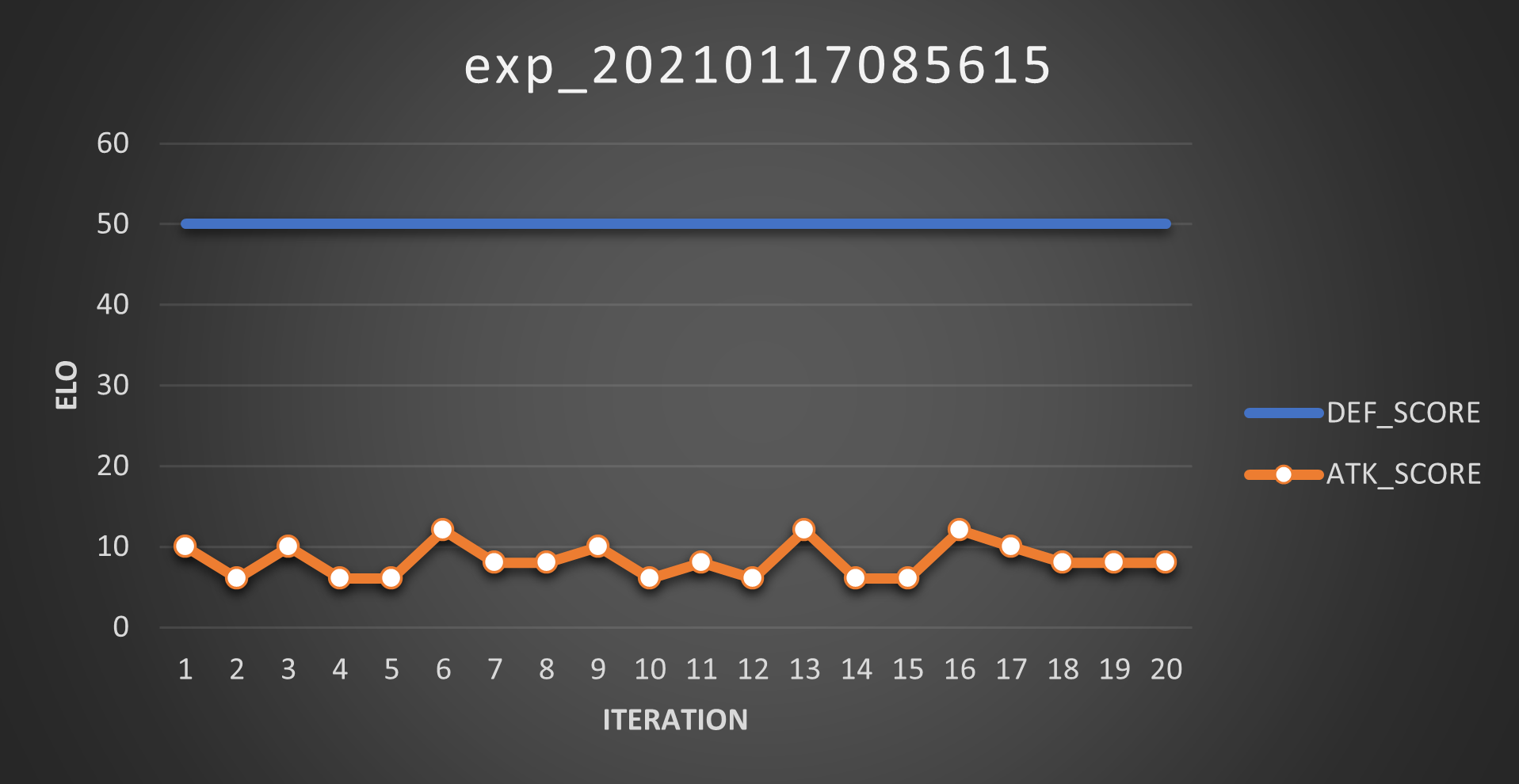
And Elos:
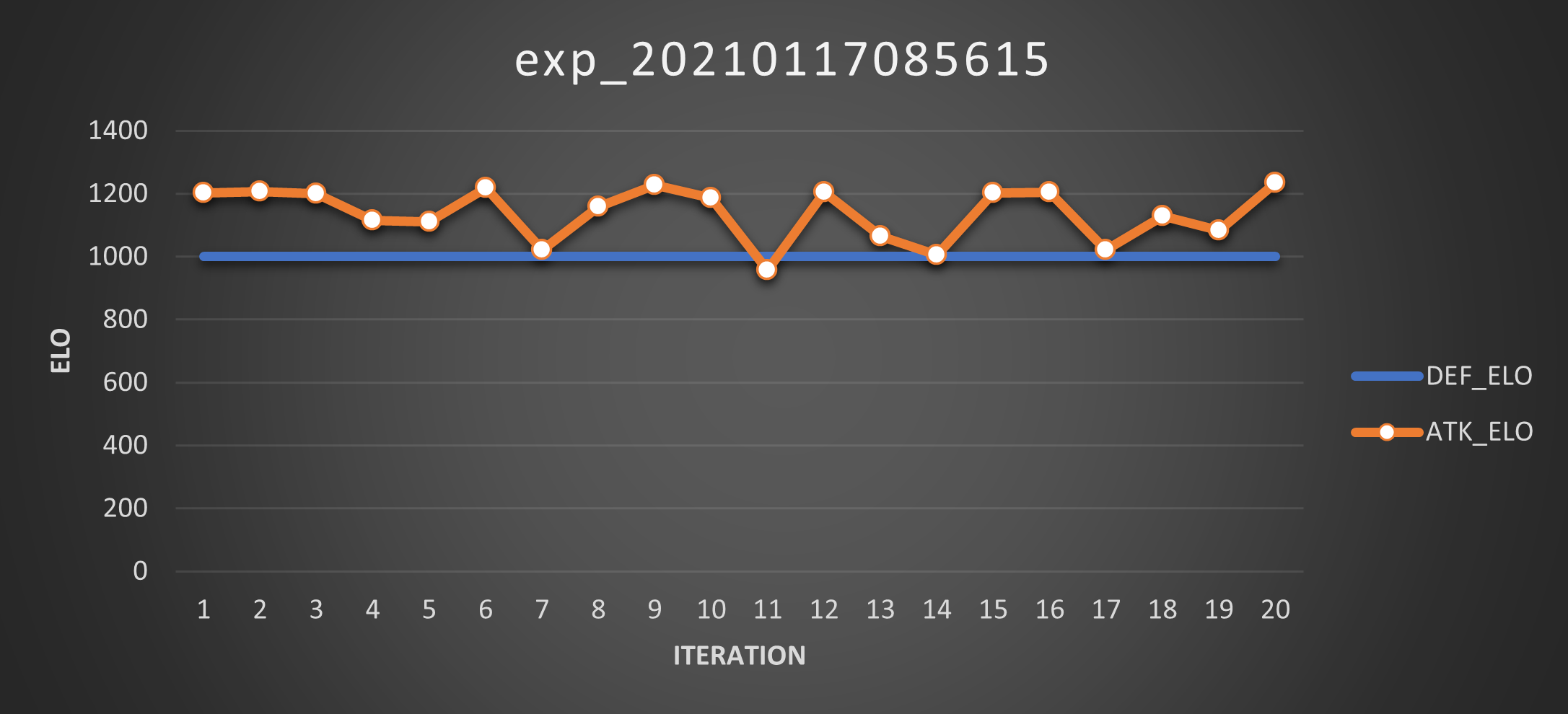
Well, this is marginally better than utter shit: the attacker sometimes evolves into something decent enough to score 12 points (best case scenario: 6 out of 25 matches won) but damn this is some noisy trend. Ideally it should be a monotonically increasing curve!
… Time to enable the elitists again, I guess 🤷♂️.
Experiment 09
So I enable the elitists feature again and increased \(\mu\) to 0.5. This was obviously the stroke of genius that I needed: the elitism would assure me I’d get a smooth (Score) curve and the larger noise would increase my chances of finding better agents.
So I ran the experiment. These are the Scores:
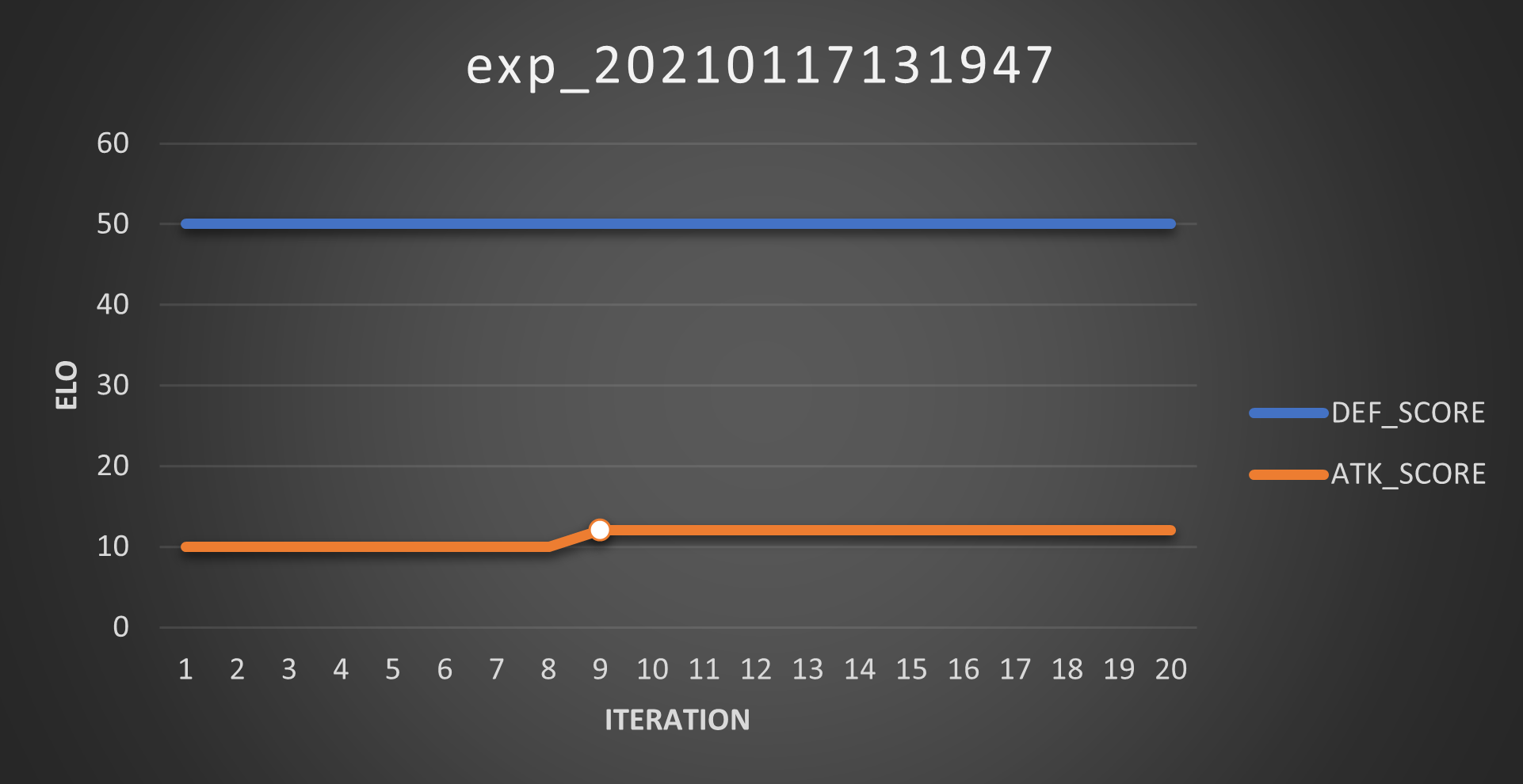
And these are the Elos:
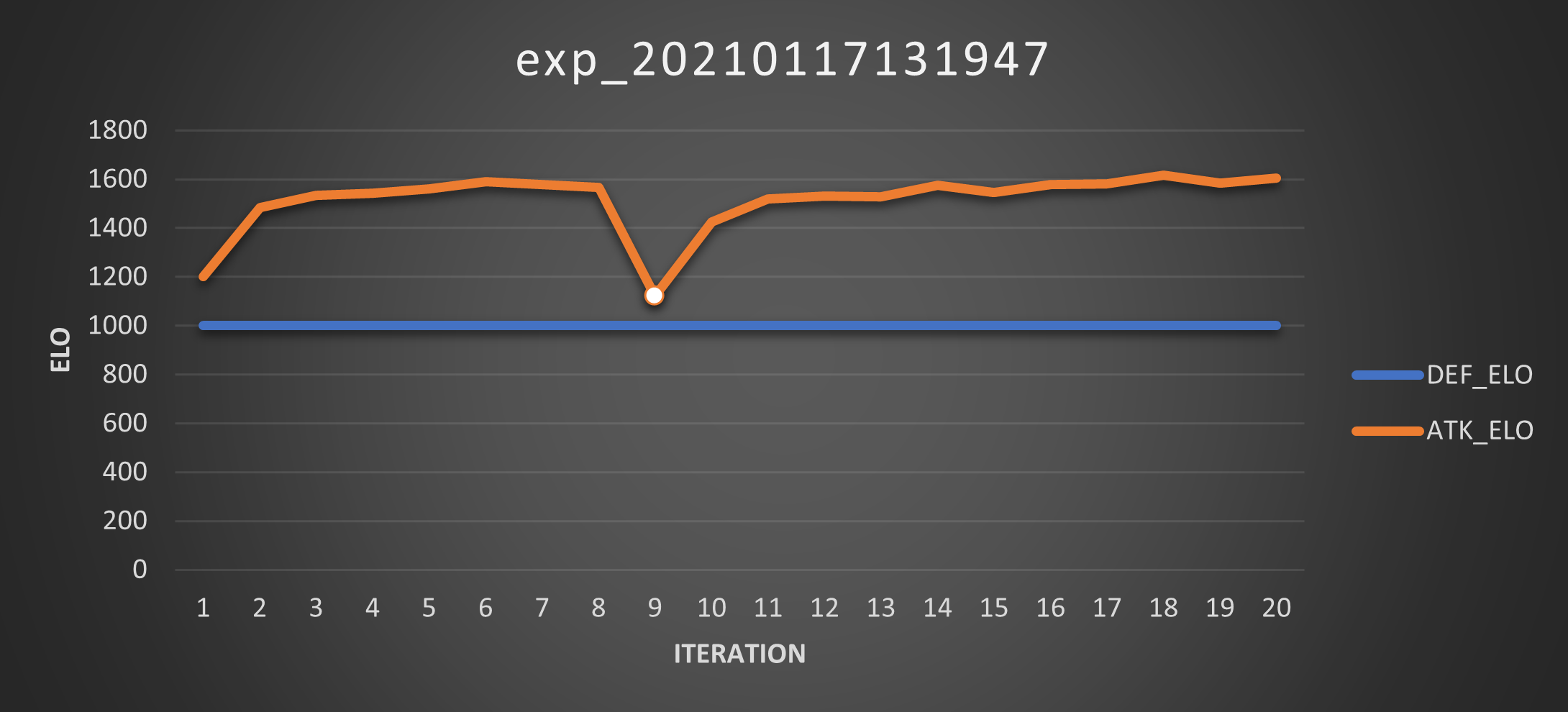
And I LOVE that little bump in the attacker’s Score curve, because it means I was right. Well, I was mostly wrong at the beginning, but then I was right.

So yeah, this proves that it is possible to obtain a better agent (after a while) and the better agent may not have a higher Elo than the previously best agent.
Conclusions
From these experiment, I now know what are the most advantageous settings to use during the training of the population and how the training process should be like.
Obviously, it’d be great to run future tests with a larger population and for more iterations (Google plz 🥺), mainly because I assume it would be possible to find better agents rather quickly.
All in all, what a weekend.